RAG re-ranking in two-stage retrieval
January 26, 2026
The big gap in retrieval is that the retriever never sees the query and document together as a whole. It only sees them as independent vectors. Meaning in a RAG setup when you ask a question, the system returns say 'K' chunks that are sort of related to the topic, but as you see none of them actually answer the query. Thats where re-ranking comes in.
RAG reranking is a second-stage step that sits down, puts the user's question and the top-K retrieved documents side-by-side, and asks: "Does this text actually answer what was asked?".
The retriever is optimized for speed and recall, so it often brings back "related" chunks. The reranker is slower (because it introduces latency) but more precise because it scores the query+chunk pair directly. (it understands the context of the question and see if the answer really answers the question)
Key idea:
- Retriever asks: "Are these two texts about similar topics?"
- Reranker asks: "Does this chunk answer this question?"
This usually boosts answer quality because the LLM gets fewer, better chunks (top-N) instead of noisy context. (instead of top-50 chunks and all, you get just the most relevant top-N chunks)
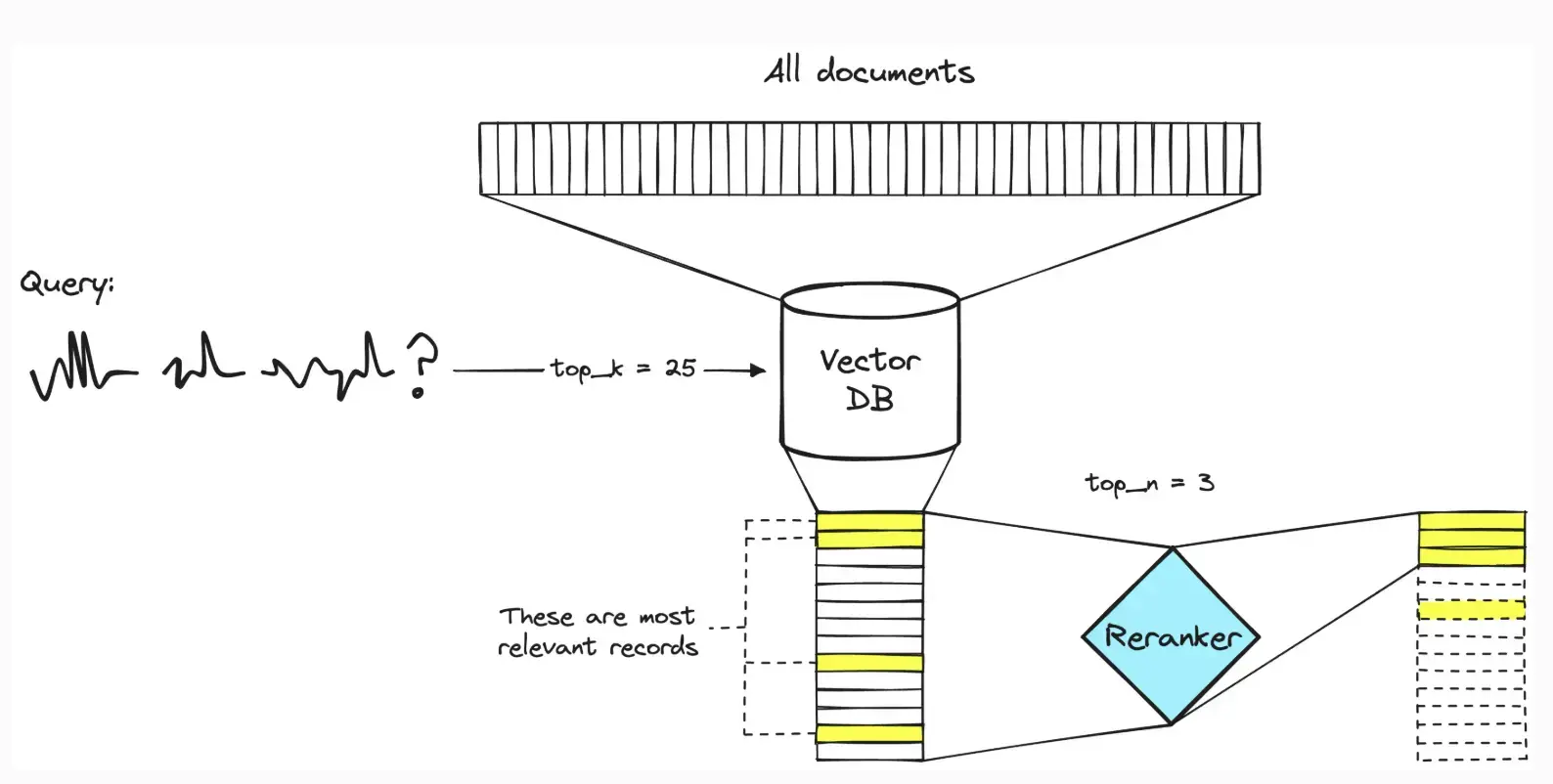
These re-rankers are usually small/light weight LLMs which are trained to do relevancy scores well. There are open source and api based re tankers
const candidates = retrieve(query, { topK: 50 });
const reranked = rerank(query, candidates); //
const context = reranked.slice(0, 5);
answerWithLLM(query, context);To read more about it: