Everything you need to know about Production ready RAG systems: Part 2
November 23, 2025
Series
- Everything you need to know about production ready RAG systems : Part 1
- Everything you need to know about production ready RAG systems : Part 3
In Part 1 of this series, we talked about data ingestion and chunking and we learned how to get raw data into the system and split it into pieces using different chunking strategies.
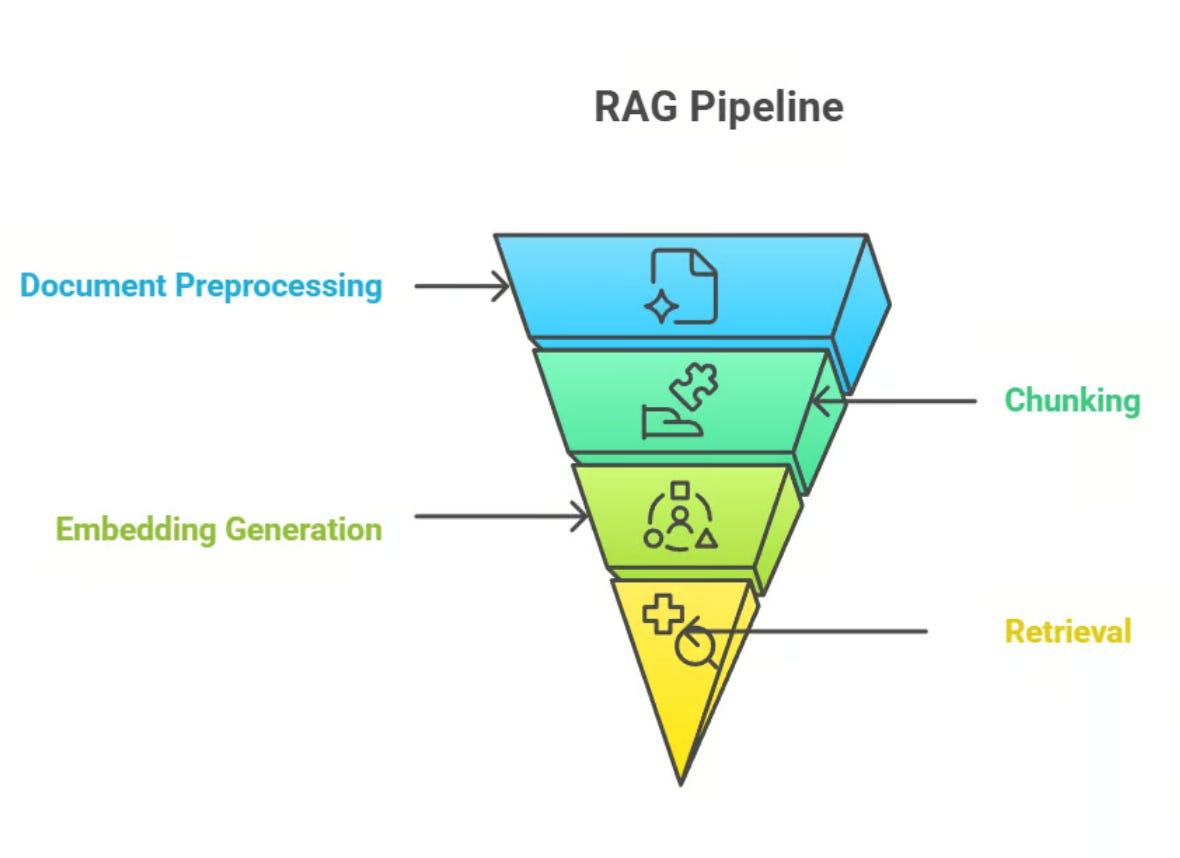
In this part, we’ll cover the last two core pieces of the RAG pipeline:
- Embedding generation – turning text into vectors that carry meaning.
- Retrieval – using those vectors to fetch the right chunks at query time.
In Part 3 we will talk about the generation step in RAG, along with different evaluation strategies to evaluate the setup of the RAG pipeline.
Embeddings: turning text into meaningful vectors
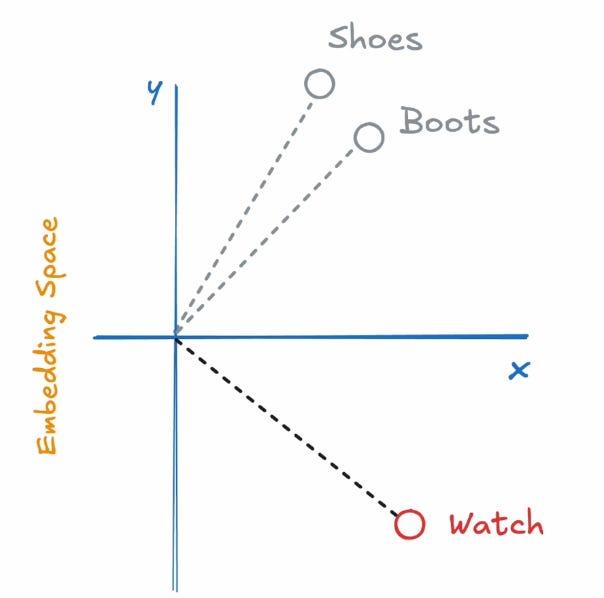
In simple terms, embeddings are numerical representations of data. These numerical representations are not random; they carry some meaning. These embeddings help in capturing the semantic meaning and similarity between data points. For instance, the words “shoes” and “boots” are related in a way that “watch” is not.
Embedding is not just for text; it can be applied to images, audio, or even graph data as well.
There are multiple embedding techniques; I can make an entire series on that. But for now to understand what makes a good embedding, these are the 2 points:
- Semantic similarity - This means that words with closer meanings or relationships are closer in the vector space than words that are less related. It uses the concept of cosine similarity.
- Dimensions - What should be the size of an embedding vector? Striking the right balance is key because there are trade offs. Lower-dimensional vectors are more efficient to keep in memory or to process, while higher-dimensional can capture intricate relationships, but are prone to overfitting.
From these embedding model families, sentence transformers are one such; sentence transformers enable the transformation of sentences into vectors in vector spaces. They represent sentences as dense vector embeddings. Traditional embedding models used to work on word-level, and sentence transformers work on a sentence level.
Some popular sentence transformers are:
1. Closed(-ish) models via API
These are the ones you call over an API:
- OpenAI (
text-embedding-3-large) - OpenAI Embedding Docs - Google Gemini (
gemini-embedding-001) - Gemini Embedding Docs
You can’t download the model or fine-tune it locally. You just send text → get back embeddings/vectors.
Think of them as black box but convenient.
2. Open(-weight) models you can run yourself
These are models where you can download the weights and run them locally or on your own cloud:
- Sentence-transformers models on Hugging Face (
all-MiniLM-L6-v2,all-mpnet-base-v2, etc.) - Gemma, LLaMA, Mistral, etc.
In these kind of models you have more control (privacy, cost, custom infra).
You can refer to this link from Hugging Face to see the topmost sentence transformers → Sentence Transformers Leaderboard
Embedding models like Gemini and OpenAI can take in huge paragraphs to compute the vectors as they are huge embedding models. Most of these models are multimodal; they can deal with images and tables, etc.
How do you decide which embedding model to use for your RAG use case? So to summarize, these are the factors to be considered:
- Size of the input - If long input sequences are to be embedded, then choose a model with larger input capacity.
- Size of embedding vector - Larger dimensionalities are more accurate but need more compute and storage.
- Size of model - Larger models are better but again require more compute and power.
- Open or closed - Open models allow you to run on your own hardware and closed are easier to setup but require API calls to get the embeddings.
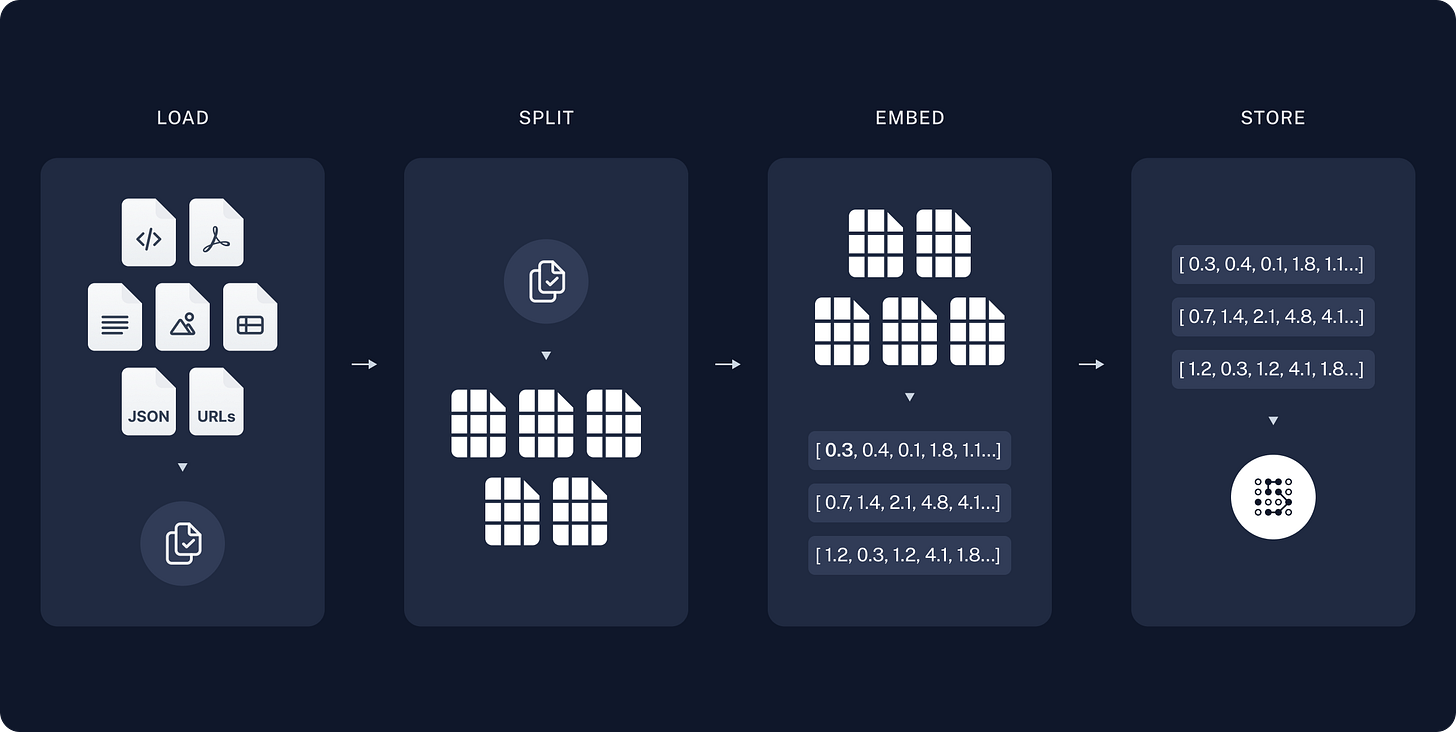
Coming back to RAG, now that we have the chunked documents based on the best chunking strategy for that particular use case, we take the embedding of these chunks.
But where do we store these embeddings of the document chunks?
Vector Databases
Well, you may say we can store these in vector databases, that’s right, but there are so many vector databases available in the market, which one would you go with? Each one of them have their own pros and use cases.
For a fact even if you pretend vector databases don’t exist, a RAG system is still totally doable with just:
- an array/tensor of embeddings, shape: (num_chunks, embedding_dim)
- some metadata structure that tells you which row corresponds to which chunk of text
No Vector DB Approach
- persistence to disk, all embeddings must fit into memory and usually when lesser number of embeddings are involved
Vector DB Approach
- db handles indexing, caching, etc.
- multiple services can read/write concurrently
- millions of chunks and embedding vectors are involved
The vector DBs that are available in the market are: (Chroma as well, missed to include that in the image)

Why do vector databases need indexing?
Every time a user asks a question, we encode that query into an embedding vector on the fly. To answer the question, we need to find the most semantically similar vectors (chunks) from our stored corpus. If we naively compare the query embedding with every stored embedding one by one, it becomes very slow as the number of chunks grows.
Vector indexes solve this by organizing embeddings in a special data structure (HNSW graphs, IVFFlat, etc.) so that we can jump directly to the most promising neighbors instead of scanning everything. That’s what makes similarity search fast enough to be usable in production RAG systems.
I can talk about different indexing techniques in a different article. The better the indexing strategy, the better and faster the retrieval would be. By default, all of these databases come up with these indexing strategies where we can choose.
For clarity, the query embeddings are not stored anywhere; they are just calculated on the fly. Only the document chunks’ embeddings are stored in the vector DB.
The same model must be used for both the document and query embedding to ensure uniformity between the two.
Retrieval
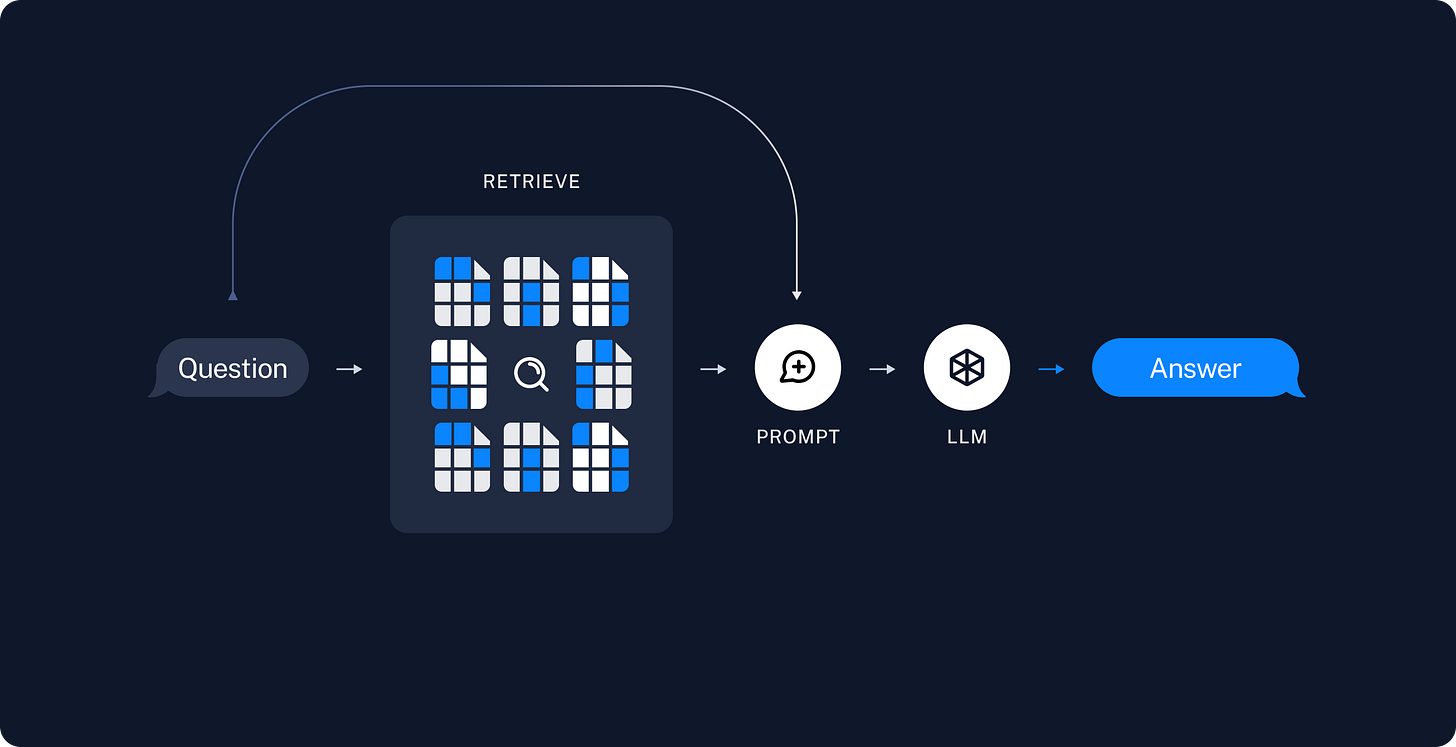
Now in the retrieval step:
- The user sends a query.
- You embed the query into a vector.
- The system compares this query embedding with all the document chunks embeddings (via a vector DB indexing).
- It retrieves the top-k (should be mentioned in our code) chunks whose embeddings are most similar to the query, using metrics like:
- cosine similarity
- Euclidean distance
- or other distance metrics supported by the vector store
These retrieved chunks are considered to be the most relevant context for the user’s question and are then passed into the generation step, which we’ll cover in Part 3, along with how to evaluate whether this whole RAG setup is actually doing a good job.
I will also try to talk about the different indexing strategies used in these vector databases.
Hope you liked this article.
If you did, please do shower some love, and do Subscribe to my weekly newsletter!
Have a nice day.
See you in the next one.