The Architect’s Guide to Caching: Strategies, Metrics, and Scaling
January 01, 2026
What is Caching ??
Caching is basically keeping a copy of data (or a computed result) in a faster place so future requests can be served quickly without doing the “expensive work” again (DB query, disk read, network call, heavy computation).
The main goal of a cache is to reduce the application latency and the load on the database.
Caching prevents repeated disk I/O, network I/O, and CPU-intensive computation, which is what makes it such a powerful lever for scaling read traffic.
Caches are super fast but also expensive and limited in size, hence we don't cache everything Instead, we strategically cache a subset of the data (hot data) that is most likely to be requested again.
| What to Cache | What not to Cache |
|---|---|
| Read-heavy data (frequently read, infrequently updated) | Highly dynamic data that changes frequently |
| Expensive computations (CPU-heavy results) | User-specific sensitive data without proper isolation |
| Database query results (stable, repeatable queries) | Data requiring strong consistency guarantees |
| API responses (third-party calls with consistent data) | Data with low hit rates (rarely accessed) |
| Rendered HTML pages (static or semi-static content) | |
| Session data (auth/session state) | |
| Static assets (images, CSS, JavaScript) |
Caching can be done at multiple places in an application. Let's look at them below.
Caching at different levels

While these five layers represent the physical locations where data is stored, we can categorize them into four broad domains based on who manages the infrastructure and how the data is shared:
-
Client-Side Caching
- Covers the browser cache; Store site-specific files (logo, CSS, JS) on the user's device. Hence provides with the lowest possible latency.
- backend control is limited and invalidation can be harder.
- Uses HTTP headers like Cache-Control, ETag, Expires, and Last-Modified.
- Best for static assets (logo, CSS, JS) that don't change often.

-
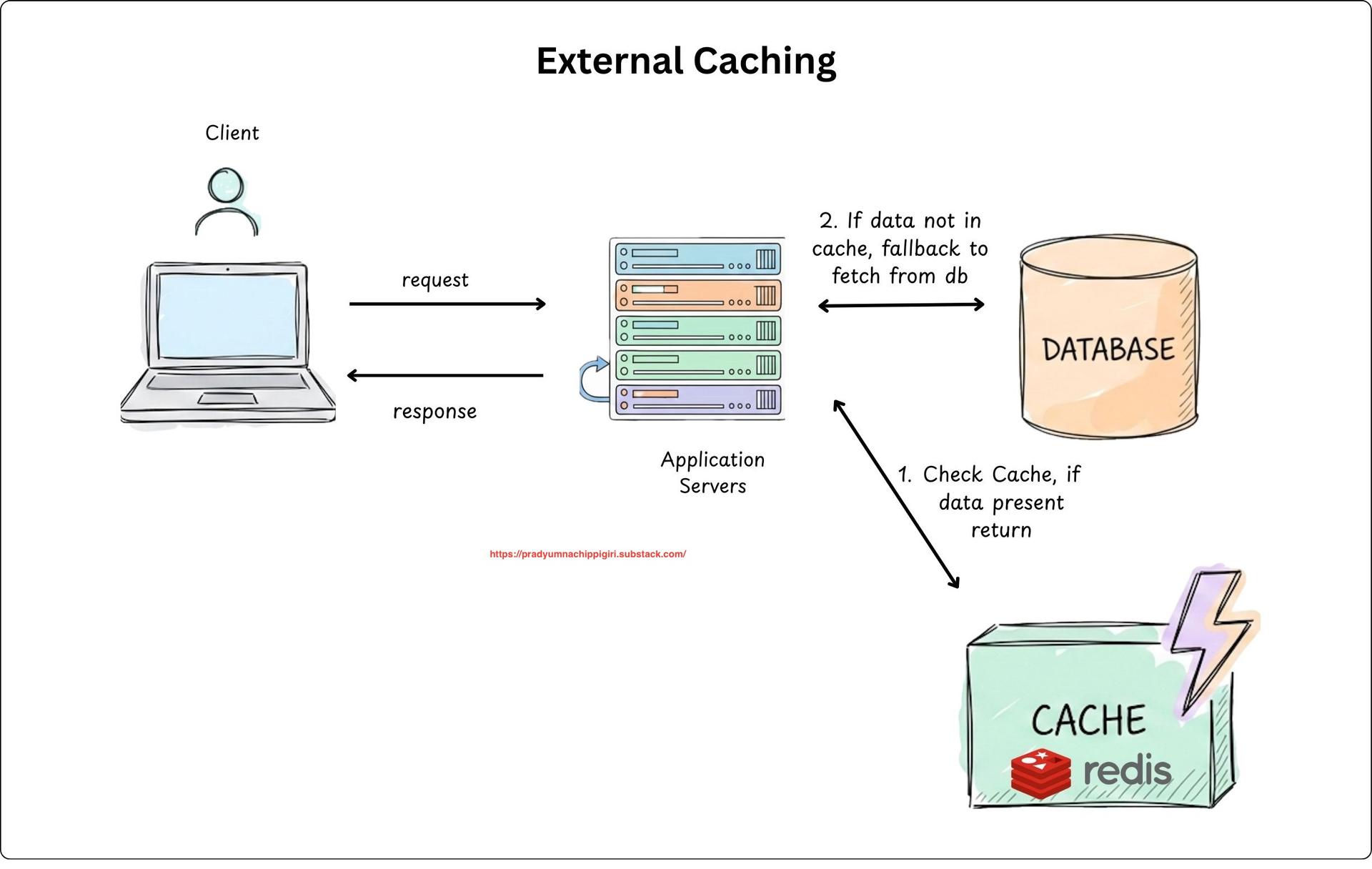
External Caching
- It’s a standalone service your app talks to. It acts as a shared memory for your entire all of our backend servers.
- Can horizontally scale well, as all application servers share the same cache (meaning cache services are decoupled from backend services.)
- Mostly used external cache are Redis, Memcached etc.
- Our backend has control over TTL, Cache invalidation and Cache eviction policies.
-
CDN
- Content Delivery Network is like a globally distributed network of servers that caches copies of our content at the edge locations instead of burdening the origin server.
- Shorter distance means faster delivery and less load on origin.
- Mostly best for static content like images, videos etc.
- 2 types of CDNs -> Push vs pull CDN? Read here: /til/system-design/pull-vs-push-cdn
-
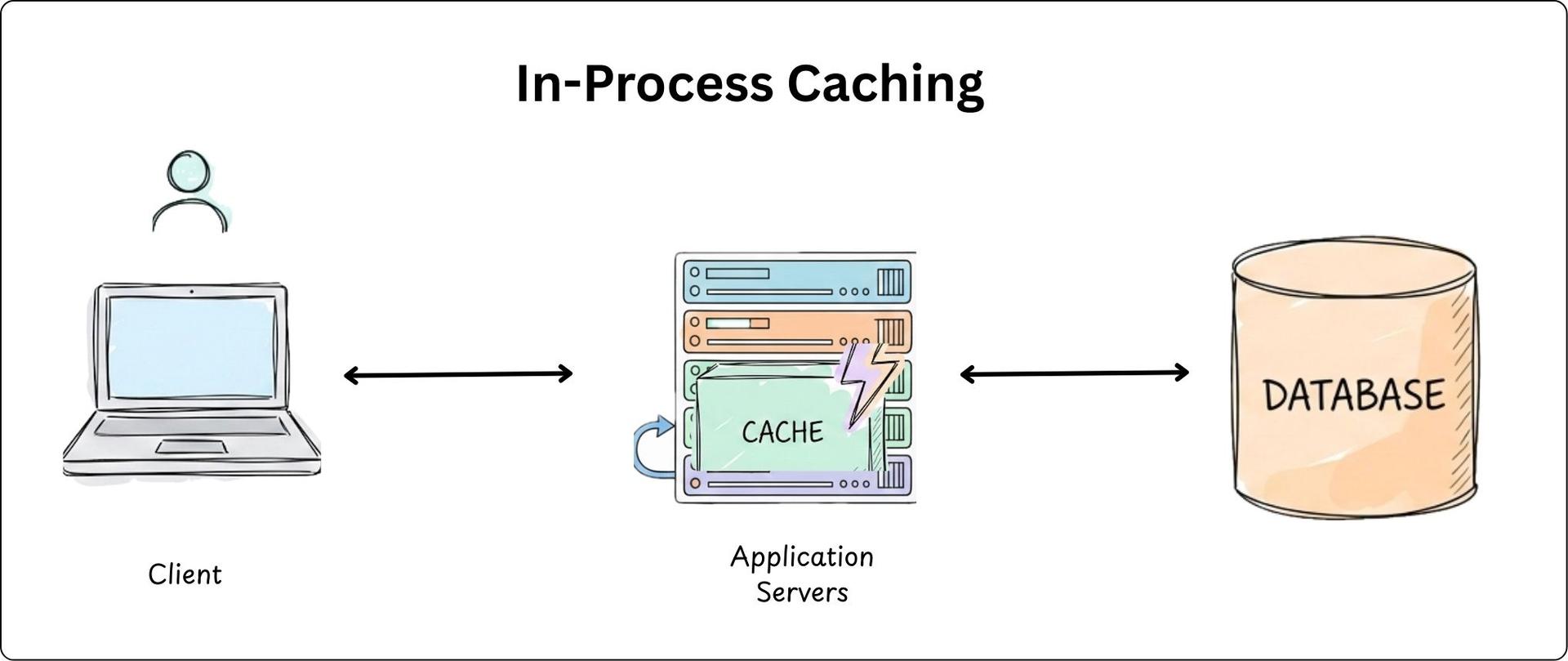
In-Process Caching
- This is caching data directly inside your server's RAM (e.g., a local Hashmap).
- It’s blazing fast (zero network call) but specific to that one server instance. If one instance updates a cache, the others won’t know.
- Useful for small, frequently requested data like configuration values, feature flags, and precomputed values.
Caching Strategies
There are 4 core caching strategies in external caching that every engineer should know. And there use-cases entirely depends on what the application and its traffic demands.
-
Read Through
 THE FLOW
THE FLOW- Application requests data specifically from the cache.
- On a miss, the cache fetches from the DB, stores it, and returns it.
LOGIC & OWNERSHIP
- The cache acts as an intermediary between the app and DB. The cache handles reading and storing automatically.
BENEFITS
- Simplifies application logic.
- Low-latency data access for cache hits.
TRADE-OFFS
- Higher latency during initial reads due to the mandatory DB query.
BEST FOR:
- Read-heavy apps like CDNs or social media feeds.
-
Cache Aside (Lazy Loading)
 THE FLOW
THE FLOW- Application checks the cache first.
- On a miss, the app retrieves from DB and manually loads it into the cache.
LOGIC & OWNERSHIP
- Application code manages the interaction between cache and DB. Data is only loaded into the cache when needed (Lazy Loading).
BENEFITS
- Highly resilient; if the cache fails, the app still functions via the DB.
- Only "hot" data is stored in the cache.
TRADE-OFFS
- Risk of stale data if the DB is updated without cache invalidation.
BEST FOR:
- High read-to-write ratios, such as e-commerce product data.
-
Write Through
 THE FLOW
THE FLOW- Every write operation is executed on both the cache and the DB at the same time.
LOGIC & OWNERSHIP
- Synchronous process ensuring both layers update as one operation.
BENEFITS
- Strong data consistency between cache and DB.
- Future reads benefit from low latency as data is already cached.
TRADE-OFFS
- Higher write latency due to the overhead of two simultaneous writes.
BEST FOR:
- Consistency-critical systems like financial or transaction apps.
-
Write Behind / Write Back
 THE FLOW
THE FLOW- Data is written to the cache first.
- The database is updated asynchronously at a later time.
LOGIC & OWNERSHIP
- Focuses on minimizing write latency by deferring database updates. Cache acts as the primary storage during the write process.
BENEFITS
- Significantly reduces write latency.
- High performance for frequent or batched write operations.
TRADE-OFFS
- Risk of data loss if the cache fails before the data syncs to the DB.
BEST FOR:
- Write-heavy scenarios like real-time analytics or "likes".
Scaling a Cache
As the system and the traffic starts getting higher, then a single node wont be able to sustain this right as the CPU/RAM runs out of memory, so thats when we start to think about scale.
Cache is similar to a DB, so scaling also is similar to a DB.
- Vertical Scaling
- Horizontal Scaling - Either Read Replicas of cache instances(mostly for read heavy traffic), or Sharding the data(incase their are more writes in the system). You can refer this to read about database scaling strategies
Once we move to Horizontal Scaling of Caches, now the data is stored across multiple nodes, so it becomes a distributed cache.
When we scale a cache horizontally, we use a hash function to decide which server stores which key (e.g., server = hash(key) % total_servers). Exactly like how we did in databases.
And if you add or remove a server, the total_servers count changes, which causes almost all keys to re-hash to different servers. So we use consistent hashing here as well.
You can read more about consistent hashing here -> Consistent Hashing article
Cache Eviction Policies
We learnt that caches have limited memory. So when the cache gets full, we need a way to remove some existing entries to make space for new ones to keep the most useful (hot) data and evicting the least useful (cold) data.
There are multiple cache eviction policies, and i have summarized the most common ones below in an image
- Least Recently Used (LRU)
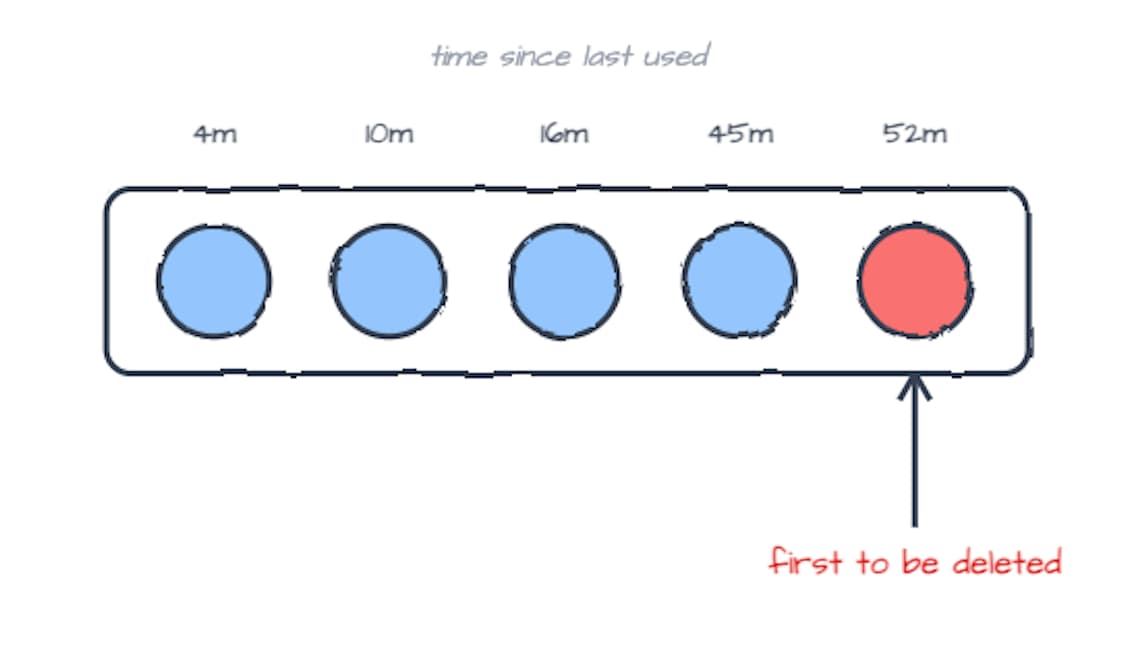
- LRU evicts the item that hasn’t been used for the longest time.
if you haven’t accessed an item in a while, it’s less likely to be accessed again soon.
- Least Frequently Used (LFU)
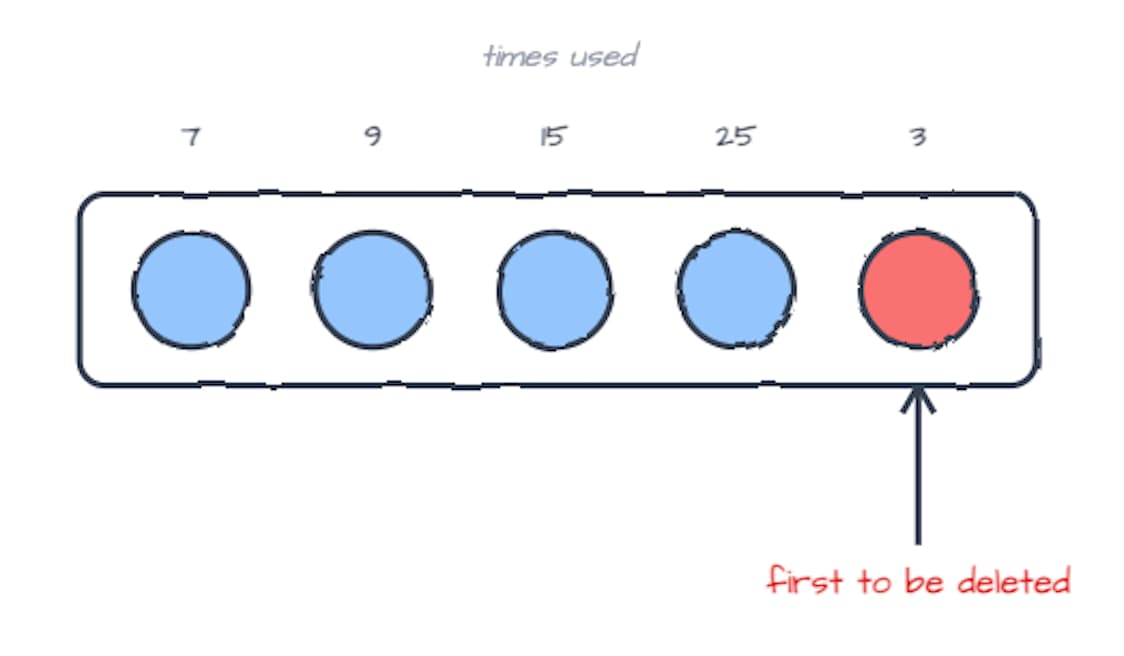
- LFU evicts the item with the lowest access count.
if something is rarely used, it’s a good candidate to remove.
- Time To Live (TTL)
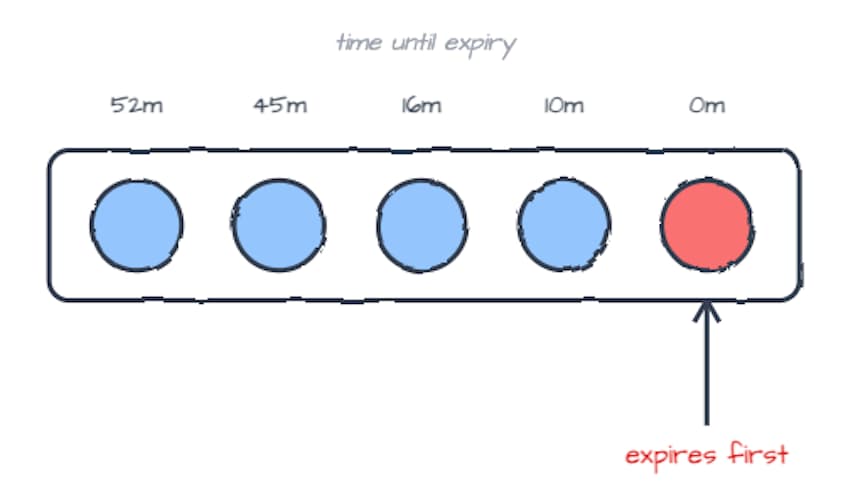
- TTL evicts items after a fixed time window or expiry.
data becomes stale after a while, so it should expire automatically.
- First In First Out (FIFO)
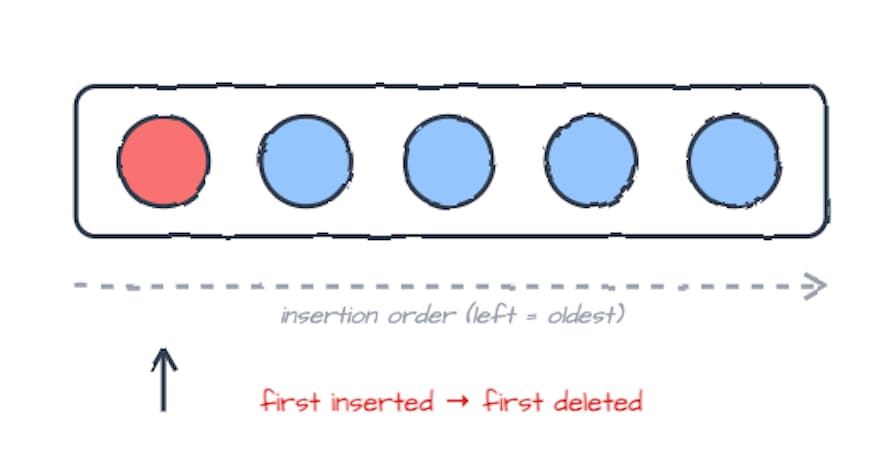
- FIFO evicts the oldest item inserted into the cache.
what came in first gets removed first, regardless of usage.
Measuring Cache Effectiveness
After implementing such a robust system , it is important to test and measure the effectiveness of the system. This can be done a few ways :

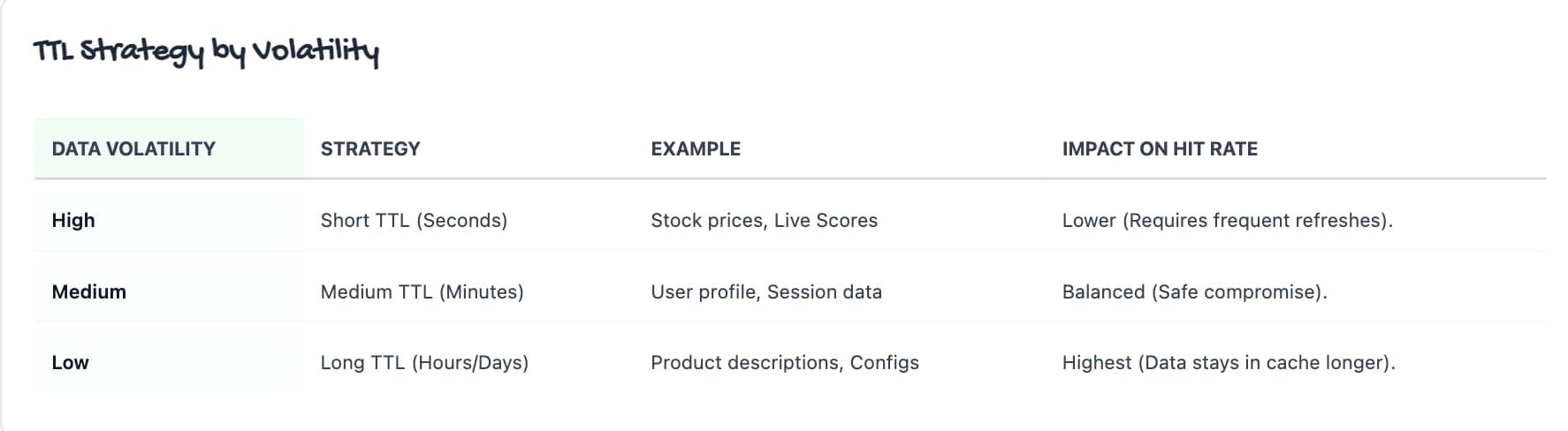
Well while discussing about the TTL based cache eviction policy, you might have got this question in mind as to whats an ideal TTL to set in any system. Well, there is no "magic number" that works for every system, the ideal TTL is always a trade-off between Data Freshness (low staleness) and System Performance (high hit rate).
The more volatile the data, the shorter the TTL must be to ensure the user doesn't see stale data.
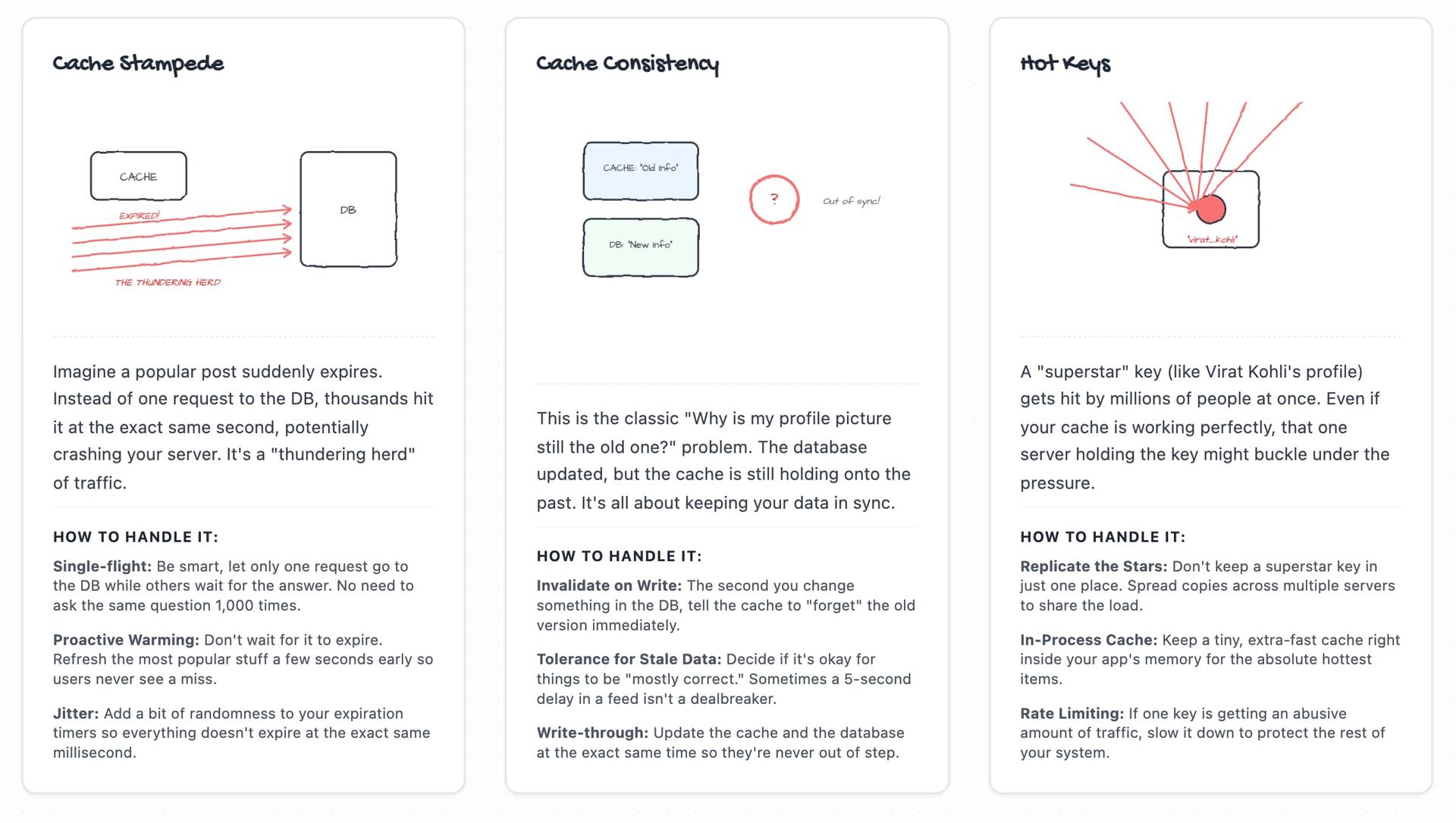
Common Edge Cases to handle in Real Systems
-
Cache Stampede
-
Cache Consistency
-
Hot Keys
Here's a wonderful gist i created; this image depicts these edge cases and how they show up in production traffic patterns.
Finally, hope this writing helped you in some ways to understand caching in real-world systems. Would like to end this article with a famous quote by Phil karlton
There are only two hard things in Computer Science: cache invalidation and naming things.
If you learned something new, and if you feel your time was worth it, then please do Subscribe to my weekly newsletter!